
Voorspellen wat de Tweede Kamer morgen gaat stemmen
CASE
Intelligence
Inzicht: we kunnen voorspellen wat de Kamer morgen gaat stemmen
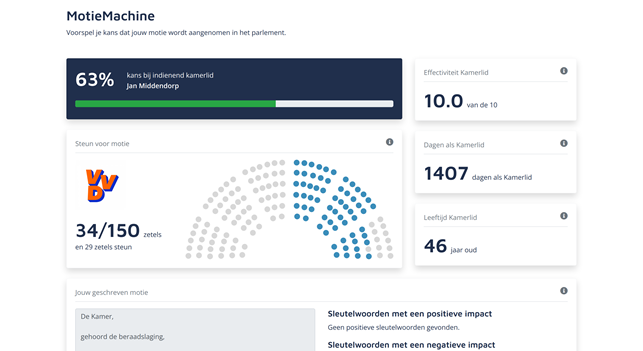
De MotieMachine voorspelt met bijna 80% accuraatheid of een motie wordt aangenomen of verworpen door de Tweede Kamer. Een belangrijk onderbuikgevoel onder lobbyisten (of van politieke junkies) is de voorspelling of een meerderheid van de Tweede Kamer vóór of tegen een motie gaat stemmen. Geef een ervaren lobbyist een stapel moties en hij of zij zal redelijk goed in staat zijn om in te schatten of een motie wordt aangenomen of niet. Dit lobbyinstinct – wat soms voelt als natte-vingerwerk – hebben wij onderbouwd met de MotieMachine.
Idee: met open data kunnen we stemmingen in de Tweede Kamer voorspellen
- Wepublic heeft de MotieMachine gebouwd met open data van de Tweede Kamer door gebruik te maken van kunstmatige intelligentie (AI). Dat hebben wij uit nieuwsgierigheid gedaan: wij willen weten welke professionele onderbuikgevoelens we kunnen valideren met kwantitatieve analyses.
- Ons vertrekpunt voor de MotieMachine was de open data van de Tweede Kamer. Hierbij hebben we ons gericht op de kabinetsperiode’s Balkenende IV en Rutte I, II en III (2008 – heden).
- Op basis van deze data zijn we gaan kijken welke drijfveren voorspellen of een motie wordt aangenomen of verworpen. In de eerste fase van ons onderzoek hebben we gekeken welke van deze drijfveren significant voorspellend zijn. Met deze drijfveren konden we een AI model trainen (een random forest model).
- Door het model op een speciale manier te bouwen, was het mogelijk om elke nacht de nieuwste moties in te lezen en het model te hertrainen. Zo kon het model zich goed aanpassen aan de snel veranderende politieke werkelijkheid.
- Het AI model kon in 79% van de moties de juiste uitkomst voorspellen (F1-score). Anders gezegd, bij 4 van de 5 moties had ons AI model gelijk.
- Uit aanvullend onderzoek van ons blijkt dat het model ook zijn slechte momenten kent. In demissionaire periodes, de periode na de verkiezingen en voordat een nieuw kabinet is gevormd, blijkt dat model verward raakte door het inconsistente stemgedrag van partijen. Er is op zo’n moment nog geen nieuw coalitieakkoord, waardoor de blokvorming anders ligt dan tijdens een missionaire periode. Ook ligt het aantal moties lager, waardoor er minder trainingsdata beschikbaar is om het model te verbeteren.
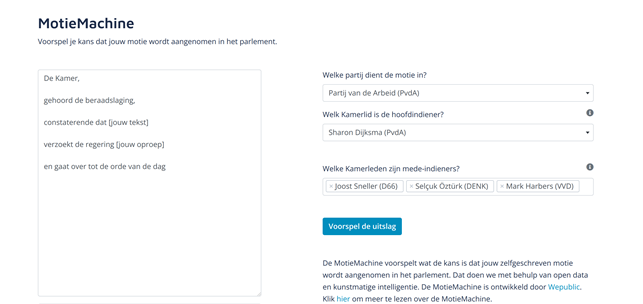
Resultaat: iedereen kan ons algoritme gebruiken om eigen moties te toetsen
- Op de website motiemachine.nl kon elke bezoeker ook zelf een eigen motie schrijven om te laten beoordelen door het AI model. In een paar weken tijd zijn meer dan 500 moties geschreven en ingediend (ook door een aantal Kamerleden en fractiemedewerkers!).
- Ook werd er op de website elke week een lijst van moties gepubliceerd waarop je kan zien over welke moties er volgende week gestemd zouden worden. Bij elke motie werd er ook een beoordeling gegeven van het AI model over de kans van slagen van die motie.
Verder lezen
- Lancering MotieMachine: Stemgedrag Kamerleden voorspellen met AI
- Carla Dik-Faber meest succesvolle Kamerlid, ChristenUnie meest succesvolle partij
- Kleine coalitiepartijen meeste invloed op belangrijkste maatschappelijke thema’s
- Vrouwen zijn succesvoller in de Tweede Kamer
De tool was beschikbaar tot december 2021 op www.motiemachine.nl.
Alle uitgelichte cases